Web Crawler System Design
Table of content:
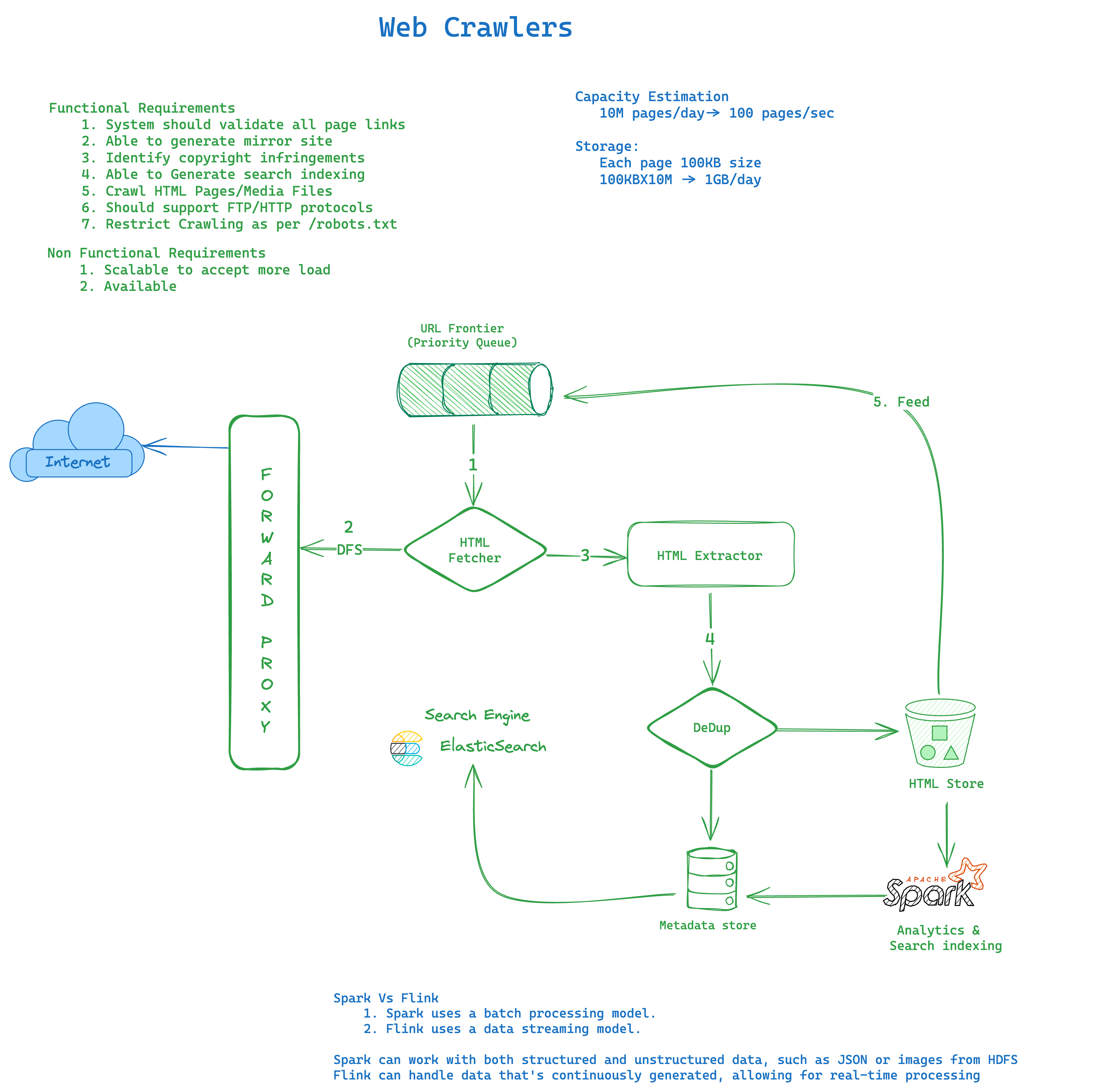
Functional Requirements
- System should download and validate pages
- System should able to generate mirror site
- System should identify copyright infringements
- Restrict crawling per /robots.txt
Non-Functional Requirements
- System should highly reliable/scalable
- System should be highly available with eventual consistency
Capacity Estimation
Throughput
- DAU :10M pages/day -> 100 pages/sec
Storage
- 100KBX10M -> 1GB/day